In a world of locked rooms,the man with the key is king.
满世界都是封锁的房间,有钥匙的人就是国王 —— Moriarty
字符编码浅谈及Python中的编码问题
做了个思维导图如下
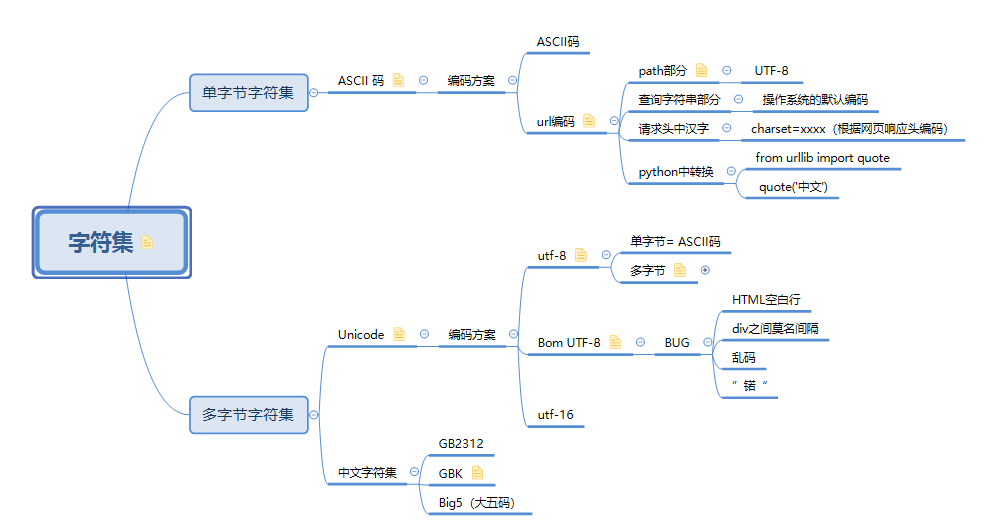
字符集(Charset)
概念
首先我们要明确一个概念,字符集是一个系统支持的所有抽象字符的集合。
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
他只是规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
分类
字符集分为单字节字符集和多字节字符集。
单字节字符集一般使用的都是ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。
通常我们所说的”ASCII码”其实是ASCII字符集和ASCII编码方案的统称。
多字节字符集常用的是Unicode(统一码、万国码、单一码、标准万国码),它可以使电脑得以体现世界上数十种文字系统。注意:它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
字符编码(Character Encoding)
###概念 这是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系。
将字符转换为电脑能识别的二进制数字的过程称为编码(encoding),反之称为解码(decoding)。
ASCII码
ACII字符集对应的是ASCII编码方案,使用7位(bits)表示一个字符,共128字符; 但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展, ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
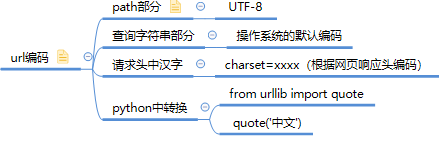
URL编码
也叫做百分号编码(Percent-encoding)。
RFC 1738规定,URL中不能包含非 ASCII 字符。
如果URL中有汉字,就必须编码后使用。
URL依据的编码方式比较混乱,差不多有以下四种情况:
UTF-8和BomUTF-8编码
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它是Unicode的一种实现或者说编码方案。
它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。
因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
BomUTF-8
BOM(byte order mark)是Unicode码点U+FEFF,是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。UTF-8因为它的编码特性,是字节序无关的,所以不需要Bom头。
所谓字节序,即是大于一个字节类型的数据在内存中的存放顺序。
Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做”零宽度非换行空格”(ZERO WIDTH NO-BREAK SPACE),用FE FF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端方式;如果头两个字节是FF FE,就表示该文件采用小端方式
微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开,但这样的文件在 Windows 之外的操作系统里会带来问题,特别是网络中尽量避免使用BomUTF-8。
「UTF-8」和「带 BOM 的 UTF-8」的区别就是有没有 BOM。即文件开头有没有 U+FEFF。
如果你使用微软的记事本编写程序(真的会有人这么做吗…)的话,默认编码会是BomUTF-8。
GBXXXX字符集&编码
GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。
微软利用GB 2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展。目前最常用的是GBK。
这一系列标准即规定了字符集又规定了编码规则,对于单个字符依然沿用了ASCII的字符集及编码规则。
UTF-16、UTF-32
都是Unicode字符集的一种编码方案,即实现。具体规则在此不再详述,有兴趣可参见文末链接。
python中的编码问题
默认编码
python2中默认使用ASCII字符集,ASCII编码规则。所以不支持中文,需要输入中文时,在文件头输入 # -*- coding: utf-8 -*-,或者# codeing=utf-8
python3默认使用Unicode字符集,UTF-8编码规则。为了增强兼容性,一般也在文件头声明编码规则。
python中字符串的两种形式
在python2中,字符串其实有两种形式:
- str(字节序列)对象
- unicode(用某种编码格式解码字节序列形成的字符串)对象
来看例子:
>>> s = "string"
>>> type(s)
<type 'str'>
>>> u = u"string" # or u = s.decode("ascii")
>>> type(u)
<type 'unicode'>
str对象更底层(byte对象),想要获得unicode对象,需要调用内建的unicode()函数。 从unicode到str的转换是使用encode。
例如u.encode(“gbk”),即是将unicode对象”u”使用”gbk”编码规则编码成str对象。
python3中,字符串默认都是unicode对象,所以python3中不能对字符串进行decode,不然会报错:
>>> s = u"string"
>>> type(s)
<class 'str'>
>>> s.decode("ascii")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'str' object has no attribute 'decode'
python3中的”str对象”也就是”字节序”对象哪里去了呢? 事实上,字节序列对象在python中等价于byte对象:
# python 2
>>> s = b"string"
>>> type(s)
<type 'str'>
# python3
>>> s = b"string"
>>> type(s)
<class 'bytes'>
编码规则的转换
若要转换编码规则则必须将字符串先解码转换为unicode对象,再对此unicode对象进行编码。
python中str.encode()实际上就等价于str.decode(sys.defaultencoding).encode()
URL编码
python2中:
import urllib
>>>urllib.quote("中文") # 这里可以使用中文是因为在win终端中默认使用了gbk编码
>>>'%D6%D0%CE%C4' # 网络中一般使用utf-8编码,这里使用的是gbk
>>> unicode_str = ("中文").decode("gbk")
>>> utf8_str = unicode_str.encode("utf-8")
>>> urllib.quote(utf8_str)
'%E4%B8%AD%E6%96%87'
python3中:
>>> import urllib.parse
>>> urllib.parse.quote("中文")
'%E4%B8%AD%E6%96%87'
将输出的url编码转换为中文只需要使用unquote方法即可。
注意点
当python2未在文件头声明编码规则为utf-8时,一定要注意:
- 程序中出现字符串时一定要加一个前缀u。
- 不要用str()函数,用Unicode()代替
- 不要用过时的string模块。如果传给它非ASCII码,它会把一切搞砸。
- 不到必须时不要在你的程序里编解码Unicode字符,只在你要写入文件或者数据库或者网络时,才调用encode()函数和decode()函数。
- 使用什么字符编码,就要采用对应的字符集进行解码
对于python3虽然默认使用utf-8规则编码,但最好依然声明,这样在将代码移植到python2解释器时避免了很多麻烦。
参考链接:
- 阮一峰:字符编码笔记:ASCII,Unicode 和 UTF-8
- 吴秦:字符集和字符编码(Charset & Encoding)
- URL 的编码
- Unicode之痛
- python中str字符串和unicode对象字符串的拼接问题
- Python 字符串与unicode对象 关于与区别 encode、decode
- python 中文编码问题总结 – str 和 unicode
- python 字符编码与解码——unicode、str和中文:UnicodeDecodeError: ‘ascii’ codec can’t decode
- 阮一峰:关于URL编码
- Unicode 和 UTF-8 有什么区别? - 于洋的回答 - 知乎
- 知乎问题:「带 BOM 的 UTF-8」和「无 BOM 的 UTF-8」有什么区别?网页代码一般使用哪个?
- Jim Liu’s Blog:编码歪传——番外篇
- wiki百科:字节顺序标记
- 彻底理解字符编码
- 大端小端(Big- Endian和Little-Endian)
- 详解大端模式和小端模式

