玫瑰与荆棘共生,香菇与毒菇同长,真实与假冒比翼腾飞。——王蒙
没那么浅地谈谈HTTP与HTTPS【二】
四、加密算法和密钥管理
介绍密钥交换机制之前先普及一些加密算法基本知识以及为什么要有密钥管理机制。
1. 加密算法
加密算法就是将普通信息(明文)转换成难以理解的数据(密文)的过程;
加解密包含了这两种算法,一般加密即同时指称加密与解密的技术。
密钥是一个用于加解密算法的秘密参数,通常只有通信者拥有。
1) 对称密钥加密
对称密钥加密是密码学中的一种加密法,是以转换其中一个数字、字母或仅字符串随机字母,一个秘密密钥会以特定的方式变更消息里面的文字或字母,例如更换字母相对位置(例如hello变成lohel)。只要寄件者与收件者知道秘密密钥,他们可以加密和解密并使用这个数据。
2.)公开密钥加密
公开密钥加密(也称为非对称加密)是密码学中的一种加密法,非对称密钥,是指一对加密密钥与解密密钥,某用户使用加密密钥加密后所获得的数据,只能用该用户的解密密钥才能够解密。如果知道了其中一个,并不能计算出另外一个。因此如果公开了其中一个密钥,并不会危害到另外一个。因此公开的密钥为公钥;不公开的密钥为私钥。
2. 单纯使用加密算法存在的问题
通信双方使用加密算法之后,需要密钥来解密和加密信息,而双方如何得到、交换密钥,并且不会被第三方窃取,或者说密钥就算被窃取也不会导致密文被解密读取呢?
1)单纯对称加密算法的困境:
如果“单纯用对称加密”,浏览器和网站之间势必先要交换“对称加密的密钥”。
如果这个密钥直接用【明文】传输,很容易就会被第三方(有可能是“攻击者”)偷窥到;如果这个密钥用密文传输,那就再次引入了“如何交换加密密钥”的问题——这就变成“先有鸡还是先有蛋”的循环逻辑了。
2)单纯非对称加密算法的困境:
基于“加密和解密采用不同的密钥”的特点,可以避开前面提到的“循环逻辑”的困境。大致的步骤如下:
第1步 网站服务器先基于“非对称加密算法”,随机生成一个“密钥对”(为叙述方便,称之为“k1 和 k2”)。因为是随机生成的,目前为止,只有网站服务器才知道 k1 和 k2。
第2步 网站把 k1 保留在自己手中,把 k2 用【明文】的方式发送给访问者的浏览器。 因为 k2 是明文发送的,自然有可能被偷窥。不过不要紧。即使偷窥者拿到 k2,也【很难】根据 k2 推算出 k1 (这一点是由“非对称加密算法”从数学上保证的)。
第3步 浏览器拿到 k2 之后,先【随机生成】第三个对称加密的密钥(简称 k)。 然后用 k2 加密 k,得到 k’(k’ 是 k 的加密结果) 浏览器把 k’ 发送给网站服务器。 由于 k1 和 k2 是成对的,所以只有 k1 才能解密 k2 的加密结果。 因此这个过程中,即使被第三方偷窥,第三方也【无法】从 k’ 解密得到 k
第4步 网站服务器拿到 k’ 之后,用 k1 进行解密,得到 k 至此,浏览器和网站服务器就完成了密钥交换,双方都知道 k,而且【貌似】第三方无法拿到 k 然后,双方就可以用 k 来进行数据双向传输的加密。
乍看以上步骤很严密,即使被第三方偷窥,第三方也难以从 k’ 解密得到 k。
但这种方法有一个致命的缺陷,就是无法防止数据篡改,也无法识别假冒的身份。
攻击方法如下:
第1步 这一步跟原先一样——服务器先随机生成一个“非对称的密钥对”k1 和 k2(此时只有网站知道 k1 和 k2)
第2步 当网站发送 k2 给浏览器的时候,攻击者截获 k2,保留在自己手上。 然后攻击者自己生成一个【伪造的】密钥对(以下称为 pk1 和 pk2)。 攻击者把 pk2 发送给浏览器。
第3步 浏览器收到 pk2,以为 pk2 就是网站发送的。 浏览器不知情,依旧随机生成一个对称加密的密钥 k,然后用 pk2 加密 k,得到密文的 k’ 浏览器把 k’ 发送给网站。 (以下是关键)
发送的过程中,再次被攻击者截获。 因为 pk1 pk2 都是攻击者自己生成的,所以攻击者自然就可以用 pk1 来解密 k’ 得到 k 然后,攻击者拿到 k 之后,用之前截获的 k2 重新加密,得到 k’‘,并把 k’’ 发送给网站。
第4步 网站服务器收到了 k’’ 之后,用自己保存的 k1 可以正常解密,所以网站方面不会起疑心。 至此,攻击者完成了一次漂亮的偷梁换柱,而且让双方都没有起疑心。
上述过程,即是传说中的中间人攻击(Man-In-The-Middle attack )。
3. 失败的原因—缺乏【可靠的】身份认证
为什么以上方案会失败?
除了提到的“攻击者具备篡改数据的能力”,还有另一点关键点——“缺乏身份认证机制”。
正是因为“缺乏身份认证机制”,所以当攻击者一开始截获 k2 并把自己伪造的 pk2 发送给浏览器时,浏览器无法鉴别:自己收到的密钥是不是真的来自于网站服务器。
假如具备某种【可靠的】身份认证机制,即使攻击者能够篡改数据,但是篡改之后的数据很容易被识破。那篡改也就失去了意义。于是我们引入“CA认证体系”。
五、CA认证体系
CA
数字证书认证机构(英语:Certificate Authority,缩写为CA),也称为电子商务认证中心、电子商务认证授权机构,是PKI(公钥基础设施)的核心执行机构,是PKI的主要组成部分,并作为电子商务交易中受信任的第三方,承担公钥体系中公钥的合法性检验的责任。
从广义上讲,认证中心还应该包括证书申请注册机构RA(Registration Authority),RA是数字证书的申请注册、证书签发的管理机构。
CA证书
CA 证书,顾名思义,就是CA颁发的证书。
人人都可以找工具制作证书。但是个人制作出来的证书是没什么用处的。
因为你【不是】权威的 CA 机关,你自己搞的证书不具有权威性。
PKI公钥基础设施
公钥基础设施(Public Key Infrastructure,简称PKI)是目前网络安全建设的基础与核心。
简单的说PKI技术就是利用公钥理论和技术建立的提供信息安全服务的基础设施,该体系在统一的安全认证标准和规范基础上提供在线身份认证,是CA认证、数字证书、数字签名以及相关安全应用组件模块的集合。
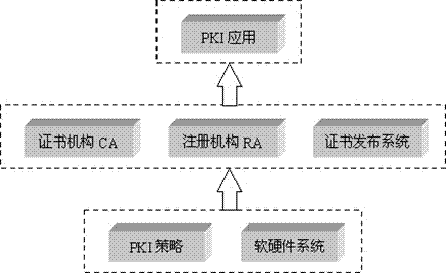
做为一种技术体系,PKI可以作为支持认证、完整性、机密性和不可否认性的技术基础,从技术上解决网上身份认证、信息完整性的抗抵赖等安全问题,为网络应用提供可靠的安全保障,但PKI不仅仅涉及到技术层面的问题。
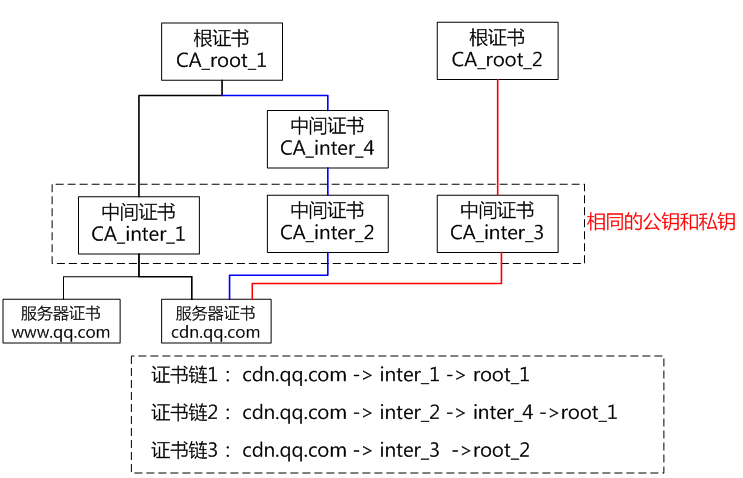
证书链
为了尽可能的保证根证书的安全性,CA中心采取了一种树状的结构:
一个root CA下面包含多个intermediates CA,然后根CA和次级CA都可以颁发证书给用户,颁发的证书分别是根证书和次级证书,最后则是用户的证书,也可以说是中级证书。
证书信任链
实际上,证书之间的信任关系,是可以嵌套的。比如,C 信任 A1,A1 信任 A2,A2 信任 A3……这个叫做证书的信任链。
只要你信任链上的头一个证书,那后续的证书,都是可以信任的。
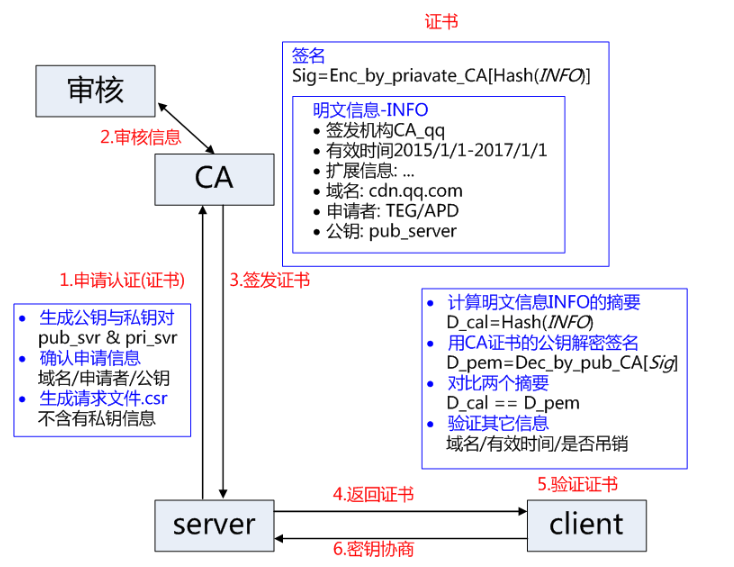
CA认证体系的基本使用
-
服务方S向第三方机构CA提交公钥、组织信息、个人信息(域名)等信息并申请认证;
-
CA通过线上、线下等多种手段验证申请者提供信息的真实性,如组织是否存在、企业是否合法,是否拥有域名的所有权等;
-
如信息审核通过,CA会向申请者签发认证文件-证书。证书包含以下信息:申请者公钥、申请者的组织信息和个人信息、签发机构 CA的信息、有效时间、证书序列号等信息的明文,同时包含一个签名;
(签名的产生算法:首先,使用散列函数计算公开的明文信息的信息摘要,然后,采用 CA的私钥对信息摘要进行加密,密文即签名。)
-
客户端 C 向服务器 S 发出请求时,S 返回证书文件;
-
客户端 C读取证书中的相关的明文信息,采用相同的散列函数计算得到信息摘要,然后,利用对应 CA的公钥解密签名数据,对比证书的信息摘要,如果一致,则可以确认证书的合法性,即公钥合法;
-
客户端验证证书相关的域名信息、有效时间等信息;
-
客户端会内置信任CA的证书信息(包含公钥),如果CA不被信任,则找不到对应 CA的证书,证书也会被判定非法。
在这个过程注意几点:
- 申请证书不需要提供私钥,确保私钥永远只能由服务器端掌握;
- 证书的合法性仍然依赖于非对称加密算法,证书主要是增加了服务器信息以及签名;
- 内置 CA 对应的证书称为根证书,颁发者和使用者相同,自己为自己签名,即自签名证书(为什么说”部署自签SSL证书非常不安全”)
- 证书= 公钥 + 申请者与颁发者信息 + 签名;
★即便有人截取服务器A证书,再发给客户端,想冒充服务器A,也无法实现。因为证书和url的域名是绑定的。

