第一次和阿北认识是在十几年前的上海,当时和Mtime的马锐拉三个人约在徐家汇的一个星巴克里,商量如何把豆瓣、VeryCD、Mtime的电影资料用开放协议打通。 那是Web2.0的黄金年代,大家都认为开放是理所应当的,各网站各司其职拼凑起一个更丰富的互联网。无需登录注册的API、RSS、XML导出都是当年的标配。
—— @Twitter:DashHuang
豆瓣逃离计划
背景
最初的豆瓣还是很理想主义的,有点像书影音类的维基百科,所有人编辑贡献条目,开放的API提供给所有人使用,拥抱开放,回馈开放。
可惜事情起了变化,互联网变得愈加封闭,豆瓣也不例外:
- 2018 年 9 月 豆瓣开放平台下线
- 2019 年 4 月 豆瓣的图书 api 无法使用
- 2020年 各电影 api 无法使用
又由于越来越多的不可抗力,越来越多的豆瓣书影音条目被删除消失,也有越来越多的豆瓣账号炸号。
不过“大事已不可问,我辈且看春光”,豆瓣的反爬只会越来越严格,奉劝诸君有意的尽快备份了罢。
关于
禀着不重复造轮子的原则,在写这个项目之前,我使用了豆瓣跑路计划 和豆瓣读书+电影+音乐+游戏+舞台剧导出工具 ,但是都不太符合我的需求。
前者导致我账号被封,而且数据也没爬下来。
后者对于有些用户必须登录,而且导出的数据缺少封面信息,不利于装逼。
另外 豆伴项目看起来不错,不过我没有Chrome浏览器,而且需要登录,又有封号风险,我个人不需要导出太多数据,所以没有尝试。
对我来说最好用的其实是豆瓣读书+电影+音乐+游戏+舞台剧导出工具 ,作者思路很强(不去爬取条目详情页,防止触发反爬),爬取速度快,除了无法导出封面,各方面都不错。
所以本项目是基于豆瓣读书+电影+音乐+游戏+舞台剧导出工具 改造而成。
Feature
- 无需登录
- 跨平台,有浏览器就能用,无需自己折腾环境
- 支持导出 看/读/玩/听 过的 电影 舞台剧/图书/游戏/音乐 为csv文件
- 导出数据含有封面
- 提供简单的Notion模板
Demo
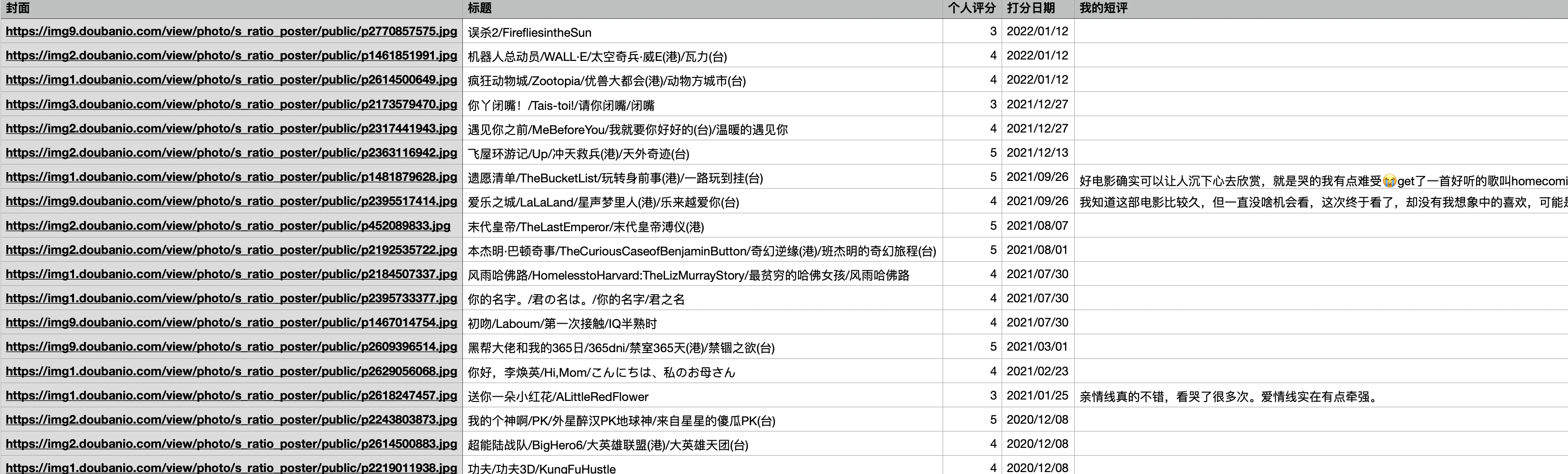
导出的数据:
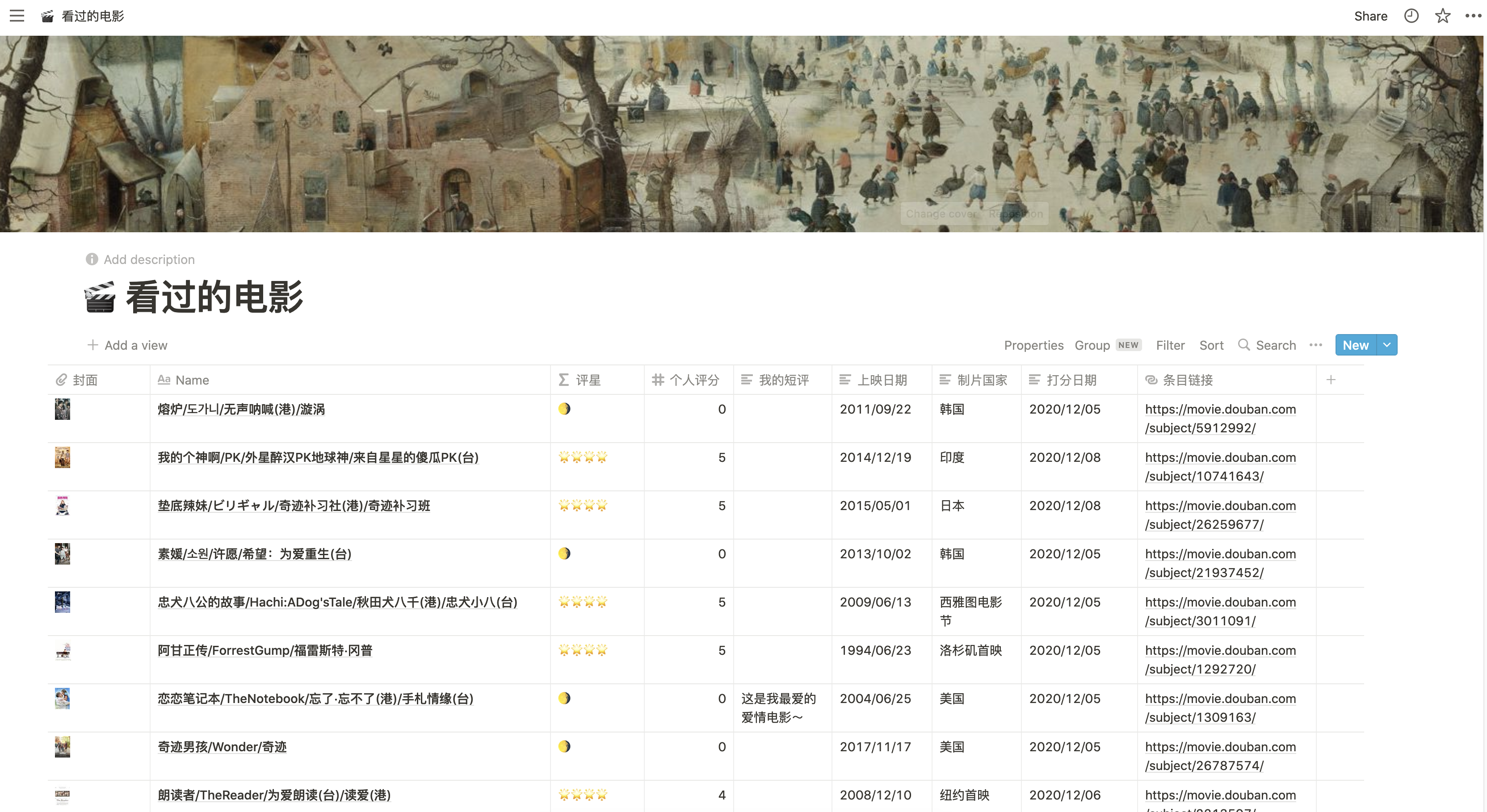
Notion页面:
Table格式:
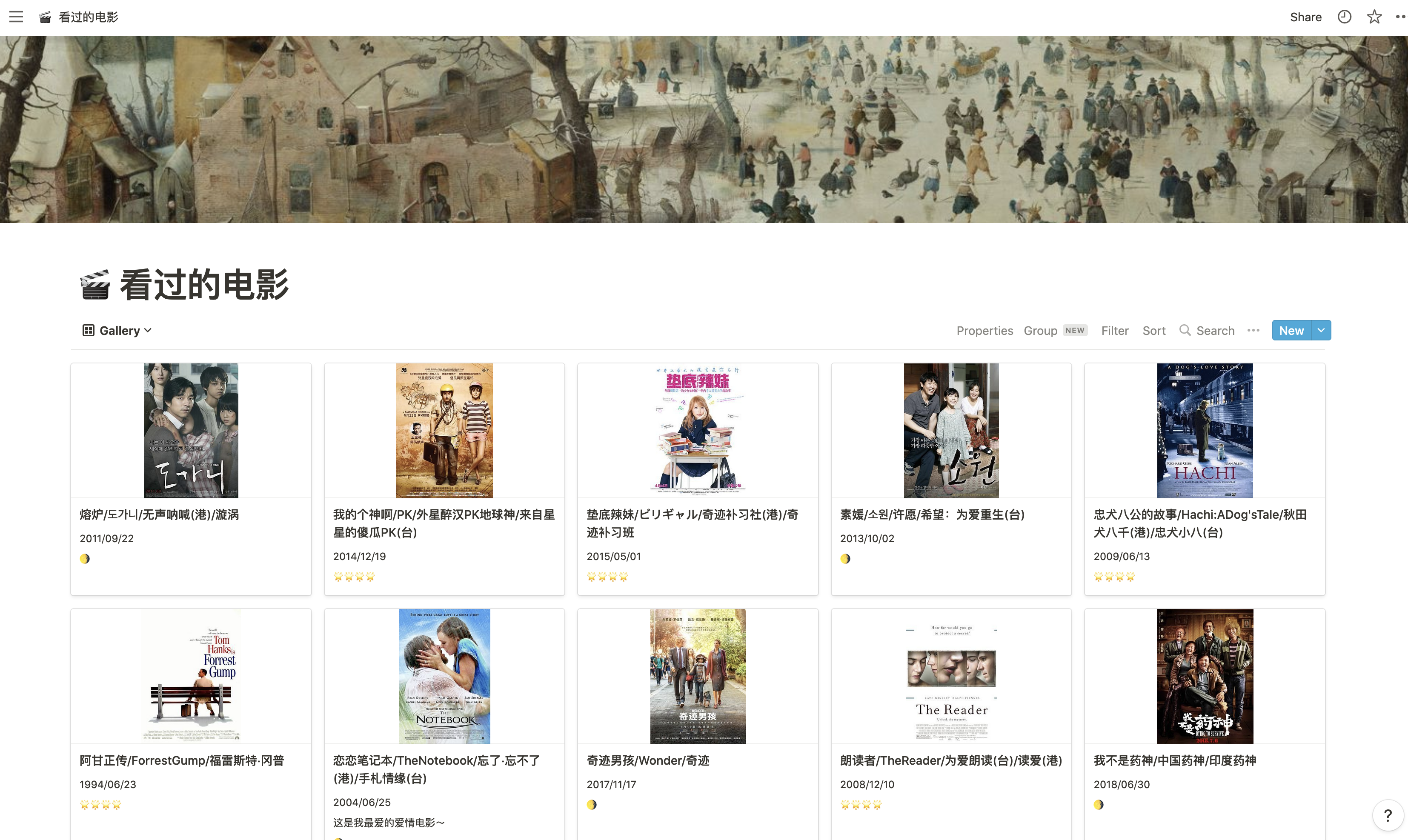
 Gallery格式:
Gallery格式:
TODO:
如果还继续更新的话
- 支持导出 想/在 读 /看/玩/听 的数据
- 增加一键导出以上所有数据
导出
安装浏览器 脚本管理器 插件
基本上有两种选择
- Tampermonkey 油猴
2.9版本以后就不开源了,而且有很多安全问题(比如会自动禁用CSP),不是很推荐。 不过使用人数最多,知名度最广,如果你已经在使用了就用它就行。
- Violentmonkey 暴力猴
完全开源,又安全的脚本管理器插件,如果你之前没有使用过它,强烈推荐你使用暴力猴。
安装脚本
访问这里
访问主页并导出
通用主页
不登录访问自己的通用主页大致有这几种方法:
- 如果你知道你的豆瓣id 直接访问
https://www.douban.com/people/{你的豆瓣id} - 如果手机登录了app,在个人主页,选择推荐- 复制链接 ,在安装了脚本的浏览器打开
- 如果可以在这里搜索自己的昵称
- 搜索引擎 搜索自己的 昵称 + site: douban.com
如果你可以直接访问,那很幸运,可以看到自己的豆瓣页面上多出几个链接:

直接点击,会自动开始导出,可能需要一点时间,中途不要做其他操作,完成后会弹出csv文件的下载提示。 然后下面的可以不用看,直接跳转到 [迁移][#迁移] 一节继续。
不过一些老用户如果没登录似乎不让直接访问主页,会自动跳转到亲切的登录页:
不过也不怕,往下看。
其他主页
虽然豆瓣限制了未登录用户 访问 个别的个人主页,但是目前(2022.02.12) 还没有限制访问 单个子项目的主页。
注: 豆瓣ID就是你主页的最后一串数字
豆瓣电影主页
https://movie.douban.com/people/{你的豆瓣id}
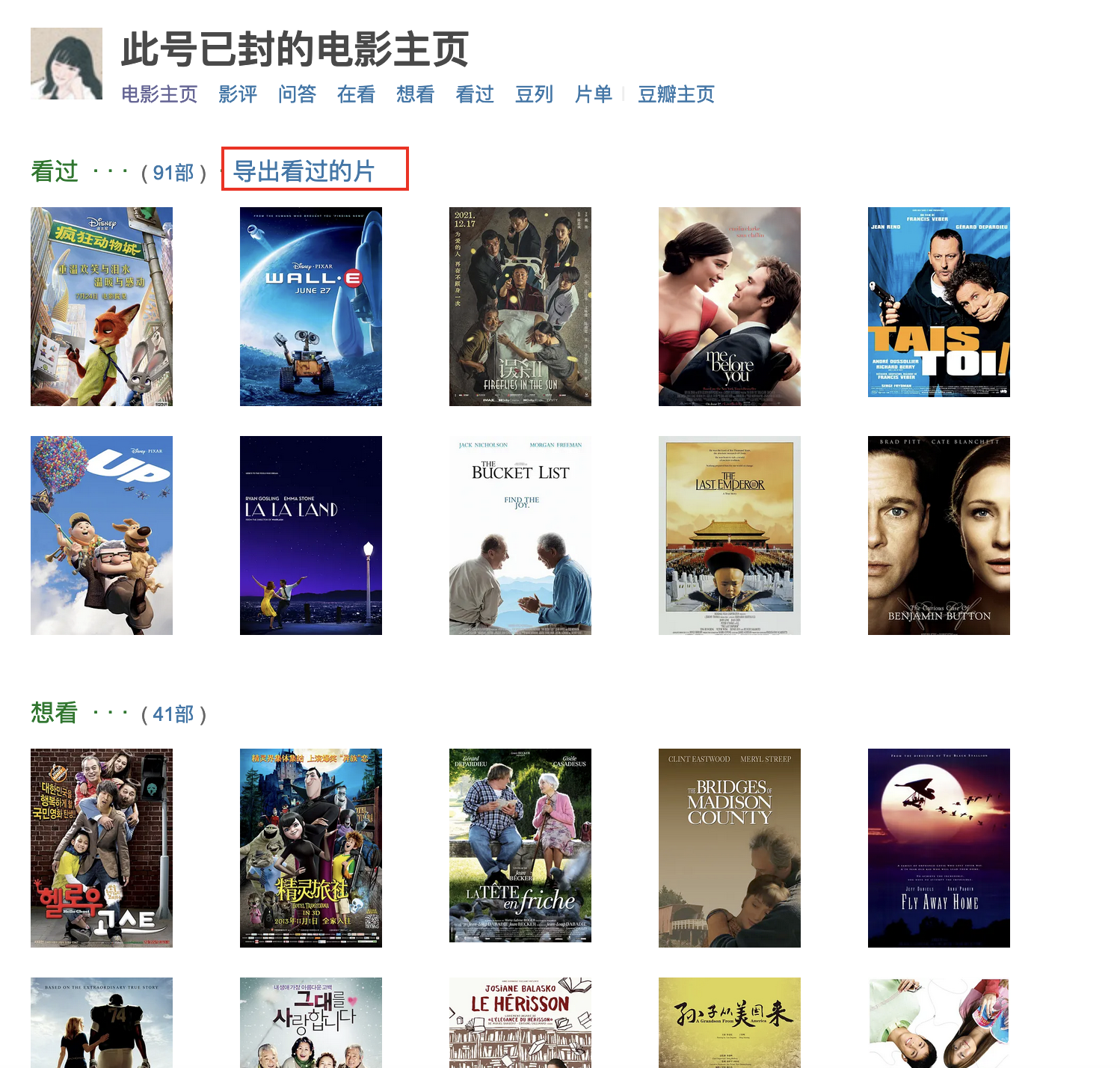
点击标记的链接即可自动开始导出,图书音乐等同理,地址如下:
豆瓣读书主页
https://book.douban.com/people/
豆瓣音乐主页
https://music.douban.com/people/{你的豆瓣id}
豆瓣游戏主页
https://www.douban.com/people/{你的豆瓣id}/games
豆瓣舞台剧主页
https://www.douban.com/location/people/{你的豆瓣id}/drama
迁移到Notion
复制模板
如果自己有更好的模板可以跳过这步。
导入
进入自己相应的note,选择刚刚导出的csv文件:

迁移到其他目的地
逃离豆瓣之后,我们还有其他选择吗?
大体有两种方向:
- 自己维护
- 优点是数据完全自己掌控,更好的隐私保护
- 缺点是需要自己维护 书影音 数据
- 使用其他更开放的服务
- 优点是不需要自己维护 书影音 数据
- 缺点是隐私和以后数据的迁移问题
自己维护
方案很多,有许多大佬自己使用excel维护,也不失为一种方案。
不过这里我只推荐上面Notion和下面Obsidian的方案:
Obsidian
这种方式更适合读书笔记比较多的用户。
效果图:


因为这种方法会搞乱我现在的知识库Vault,所以我没有使用这种方法。
这里说下大概的思路:
- 可以使用obsidian-kindle-plugin将kindle的读书笔记导入Obsidian
- 新的读书笔记设置好
YAML Front Matter,使用Templater + Quikadd新建 - 使用Dataview + Gallery 回顾统计和展示
用到的插件:Templater + Quikadd + Dataview + Gallery 如果对Obsidian管理读书记录的方式感兴趣,推荐这篇文章:Obsidian工作流
使用其他更开放的服务
推荐两个联邦宇宙相关的服务
NeoDB
一个刚起步的开源项目,需要先持有Maston或者Pleroma账号,可以标记书籍、电影、音乐和游戏,数据非常全面,除了豆瓣条目之外,还有GoogleBooks、Goodreads、Steam、Spotify、Bandcamp、IMDB、TMDB、Bangumi的数据。
目前支持导入自己的豆瓣数据,具体使用方法参见 转移某网站书影音标记。 似乎也可以方便地把自己的数据从NeoDB导出。
【注意】
- 对于NeoDB授权风险的讨论,站长改进的进度可查看站长主页
- 虽然代码开源,但是数据为站长私有,很多条目未登录的话是看不了的, 从这点看开放性不如当初的豆瓣。
- 虽然账号系统依托于去中心化的联邦宇宙,但是本身并不是去中心化的,是站长一人在维持。
BookWyrm
江尚寒翻译为书蛊,与Mastodon(长毛象)同属联邦宇宙的一员,开源,自带社交功能,缺点是只能标记 书籍,未有电影和音乐等其他数据。
这里是已有的中文书籍列表,条目还比较少,具体使用可以参见“联邦宇宙”漫游指南(6)从douban到bookwyrm
同步(可选)
其实不太推荐这种方式,既然决心逃离豆瓣,就该彻底点。 但是有些用户可能还是割舍不掉豆瓣的便捷,毕竟目前还没有可以完全替代豆瓣的产品。
目前一个比较可行的方法是,使用 GitHub Actions 定时从 RSS 信息将豆瓣标记更新同步到 Notion:
最后
因为本工具爬取的并不是 具体条目页面,所以页面访问限制不太严格,只是导出自己的数据完全足够, 我测试时没有登录,大概测试数万条数据才开始限制IP。

但局限也很明显, 就是这里无法准确获取更多有关条目本身的信息,比如电影条目的 IMDb 链接、制片国家,也无法精准把导演和演员之类的人名区分开。
如果有能力的同学可以参考下面的API做更强大的功能:
电影API
只找到一个可以使用的项目,可以根据豆瓣Subject ID查询电影信息:
https://api.wmdb.tv/movie/api?id=doubanid
如果需要电影条目更详尽的信息,可以使用这个API自己写程序补全。
图书API
如果能得到图书的ISBN号,可以调取这两个项目的API:
-
https://jike.xyz/api/isbn.html
-
https://github.com/qiaohaoforever/BambooIsbn
我最初的想法是先爬取图书条目的ISBN,然后从他处查询补全信息,但是从个人页面的条目信息无法获取,需要进入条目详情页才能得到,这样会触发反爬机制,遂作罢。

